本文最后更新于 2024年7月24日 下午
负载均衡算法
负载均衡 指的是将用户请求分摊到不同的服务器上处理,以提高系统整体的并发处理能力以及可靠性。负载均衡服务可以有由专门的软件或者硬件来完成,一般情况下,硬件的性能更好,软件的价格更便宜
当请求量过大时,单节点会无法承载庞大的流量从而崩溃。
所以在一些流量较大的服务上,我们会设置多个节点服务器处理请求,并使用负载均衡的思想 将请求分摊到每个节点上
1
2
3
4
5
6
7
8
9
10
11
|
public interface LoadBalance {
String balance(List<String> addressList);
void addNode(String node) ;
void delNode(String node);
}
|
随机算法
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
1
2
3
4
5
6
7
8
9
10
11
| public class RandomLoadBalance implements LoadBalance {
@Override
public String balance(List<String> addressList) {
Random random=new Random();
int choose = random.nextInt(addressList.size());
System.out.println("负载均衡选择了"+choose+"服务器");
return null;
}
public void addNode(String node){} ;
public void delNode(String node){};
}
|
原理:随机法将请求随机分配到各个服务器。
优点
- 分配较为均匀,避免了轮询法可能出现的连续请求分配给同一台服务器的问题。
- 使用简单,不需要复杂的配置。
缺点
- 随机性可能导致某些服务器被频繁访问,而另一些服务器则相对较少,这取决于随机数的生成情况。
- 如果服务器配置不同,随机法可能导致负载不均衡,影响整体性能。
轮询算法
核心思想: 把来自请求轮流分配给内部中的服务器,从1开始,直到N(内部服务器个数),然后重新开始循环。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public class RoundLoadBalance implements LoadBalance {
private int choose=-1;
@Override
public String balance(List<String> addressList) {
choose++;
choose=choose%addressList.size();
System.out.println("负载均衡选择了"+choose+"服务器");
return addressList.get(choose);
}
public void addNode(String node) {};
public void delNode(String node){};
public synchronized String balanceWithLock(List<String> addressList) {
choose++;
if(choose == addressList.size())
choose = 0;
System.out.println("负载均衡选择了" + choose + "服务器");
return addressList.get(choose);
}
}
|
原理:轮询法将所有请求按顺序轮流分配给后端服务器,依次循环。
优点
- 简单易实现。
- 无状态,不保存任何信息,因此实现成本低。
缺点
- 当后端服务器性能差异大时,无法根据服务器的负载情况进行动态调整,可能导致某些服务器负载过大或过小。
- 如果服务器配置不一样,不适合使用轮询法。
IP_Hash算法
hash(ip)%N算法,通过一种散列算法把客户端来源IP根据散列取模算法将请求分配到不同的服务器上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class IPHashBalance implements LoadBalance {
@Override
public String balance(List<String> addressList) {
String clientIP = "127.0.0.1";
int hashCode = clientIP.hashCode();
int index = hashCode % addressList.size();
return addressList.get(index);
}
@Override
public void addNode(String node) {}
@Override
public void delNode(String node) {}
}
|
加权轮询算法
该算法中,每个机器接受的连接数量是按权重比例分配的。这是对普通轮询算法的改进,比如你可以设定:第三台机器的处理能力是第一台机器的两倍,那么负载均衡器会把两倍的连接数量分配给第3台机器,轮询可以将请求顺序按照权重分配到后端。只是在获取服务器地址之前增加了一段权重计算的代码,根据权重的大小,将地址重复地增加到服务器地址列表中,权重越大,该服务器每轮所获得的请求数量越多。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
public class WeightRoundLoadBalance implements LoadBalance {
private static Integer choose = -1;
@Override
public synchronized String balance(List<String> addressList) {
Map<String, Integer> map = new HashMap<>();
for(int i = 0; i < addressList.size(); ++i) {
map.put(addressList.get(i), i + 1);
}
List<String> serverList = new ArrayList<>();
for(Map.Entry<String, Integer> entry : map.entrySet()) {
String address = entry.getKey();
int weight = entry.getValue();
for(int i = 0; i < weight; ++i) {
serverList.add(address);
}
}
choose++;
if(choose >= serverList.size())
choose = 0;
System.out.println("加权轮询算法选择了" + choose + "服务器");
return serverList.get(choose);
}
@Override
public void addNode(String node) {
}
@Override
public void delNode(String node) {
}
}
|
加权随机算法
加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| public class WeightRandomLoadBalance implements LoadBalance {
@Override
public synchronized String balance(List<String> addressList) {
Map<String, Integer> map = new HashMap<>();
for(int i = 0; i < addressList.size(); ++i) {
map.put(addressList.get(i), i + 1);
}
List<String> serverList = new ArrayList<>();
for(Map.Entry<String, Integer> entry : map.entrySet()) {
String address = entry.getKey();
int weight = entry.getValue();
for(int i = 0; i < weight; ++i) {
serverList.add(address);
}
}
Random random=new Random();
int choose = random.nextInt(addressList.size());
System.out.println("负载均衡选择了"+choose+"服务器");
return addressList.get(choose);
}
@Override
public void addNode(String node) {
}
@Override
public void delNode(String node) {
}
}
|
一致性哈希算法
传统Hash算法思路
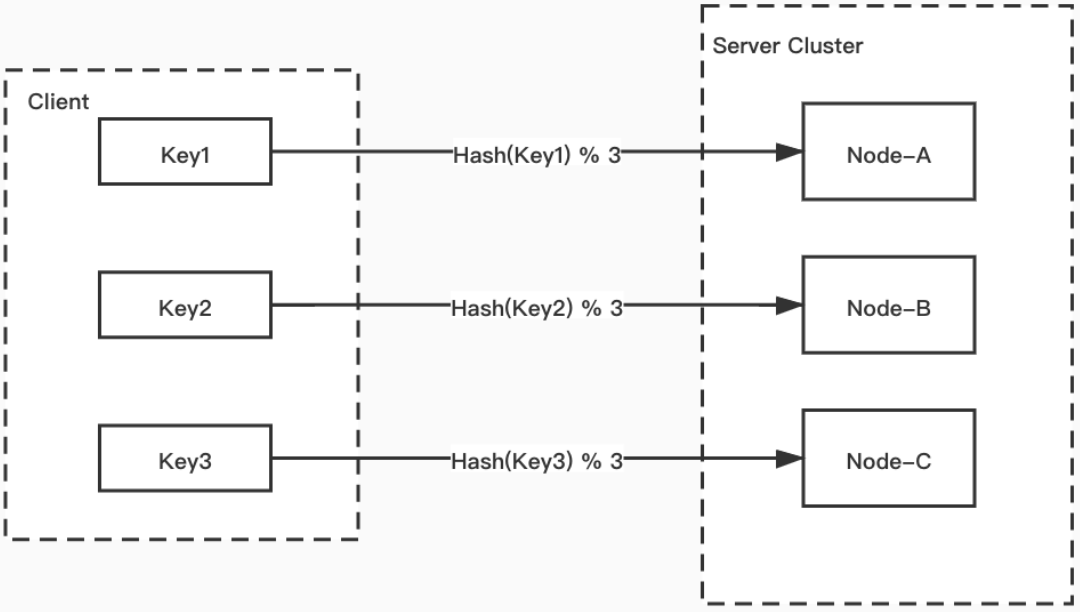
传统hash算法思路:
- 先计算 key 对应的 hash 值
- 将 hash 值和服务节点的数量取模,算出对应节点的下标,即 Hash(Key) % NodeSize
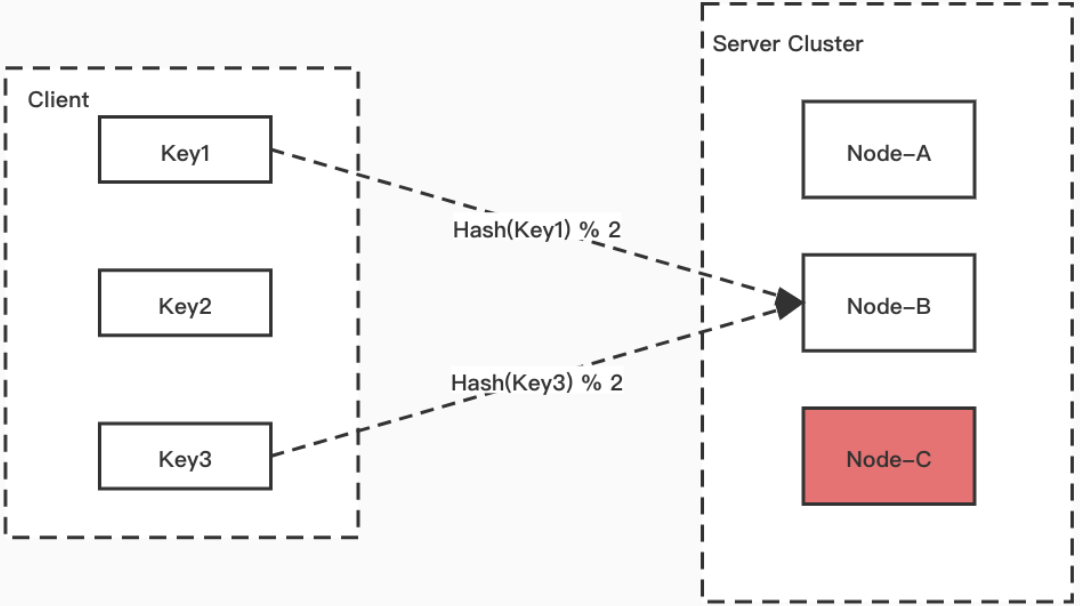
可能出现的问题:
- 如果 Node-C 节点宕机了,Hash(Key) % NodeSize 公式的取模对象发生变化,最终可能导致 Key1,Key2 的映射到的服务节点都发生变化(Key3 肯定会改变)。
- 原本 Key1 映射到 Node-A 变为映射到 Node-B,因为数据之前存储在 Node-A,则导致 Key1 无法正常命中数据;Key2,Key3 … KeyN 都可能出现这种情况。
传统 hash算法的局限性主要体现在:
- 节点数量发生变化,导致 key -> 节点的映射关系发生变化,最终导致数据存储服务不可用(之前存储的 key 无法正常命中数据)。
- 节点数量发生变化,整体数据 Rehash 的成本较高。
一致性Hash算法思路
一致性hash算法一共分三步:
- 一致性哈希算法将整个哈希值空间按照顺时针方向组织成一个虚拟的圆环,称为 Hash 环。
- 接着将各个服务器使用 Hash 函数进行哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,从而确定每台机器在哈希环上的位置。
- 最后使用算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针寻找,第一台遇到的服务器就是其应该定位到的服务器。
Hash环偏斜
问题描述
首先在节点较少的情况下数据的分布可能是不平衡的情况。
一个节点宕机之后,数据需要落到距离他最近的节点上,会导致下个节点的压力突然增大,可能导致雪崩,整个服务挂掉。
解决方案
通过引入虚拟节点,使节点最大程度的分布均匀,解决数据倾斜的问题。
“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一实际个节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
这样就成功的将所有数据较为均匀的分不到了所有的节点上,即使发生了某个节点宕机的情况,也不会对下游节点突然造成巨大负载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
| public class ConsistencyHashBalance implements LoadBalance {
private static final int VIRTUAL_NUM = 5;
private static SortedMap<Integer, String> shards = new TreeMap<Integer, String>();
private static List<String> realNodes = new LinkedList<String>();
private static String[] servers =null;
private static void init(List<String> serviceList) {
for (String server :serviceList) {
realNodes.add(server);
System.out.println("真实节点[" + server + "] 被添加");
for (int i = 0; i < VIRTUAL_NUM; i++) {
String virtualNode = server + "&&VN" + i;
int hash = getHash(virtualNode);
shards.put(hash, virtualNode);
System.out.println("虚拟节点[" + virtualNode + "] hash:" + hash + ",被添加");
}
}
}
public static String getServer(String node,List<String> serviceList) {
init(serviceList);
int hash = getHash(node);
Integer key = null;
SortedMap<Integer, String> subMap = shards.tailMap(hash);
if (subMap.isEmpty()) {
key = shards.lastKey();
} else {
key = subMap.firstKey();
}
String virtualNode = shards.get(key);
return virtualNode.substring(0, virtualNode.indexOf("&&"));
}
public void addNode(String node) {
if (!realNodes.contains(node)) {
realNodes.add(node);
System.out.println("真实节点[" + node + "] 上线添加");
for (int i = 0; i < VIRTUAL_NUM; i++) {
String virtualNode = node + "&&VN" + i;
int hash = getHash(virtualNode);
shards.put(hash, virtualNode);
System.out.println("虚拟节点[" + virtualNode + "] hash:" + hash + ",被添加");
}
}
}
public void delNode(String node) {
if (realNodes.contains(node)) {
realNodes.remove(node);
System.out.println("真实节点[" + node + "] 下线移除");
for (int i = 0; i < VIRTUAL_NUM; i++) {
String virtualNode = node + "&&VN" + i;
int hash = getHash(virtualNode);
shards.remove(hash);
System.out.println("虚拟节点[" + virtualNode + "] hash:" + hash + ",被移除");
}
}
}
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
@Override
public String balance(List<String> addressList) {
String random= UUID.randomUUID().toString();
return getServer(random,addressList);
}
}
|
原理:一致性哈希法将输入(如客户端IP地址)通过哈希函数映射到一个固定大小的环形空间(哈希环)上,每个服务器也映射到这个哈希环上。客户端的请求会根据哈希值在哈希环上顺时针查找,遇到的第一个服务器就是该请求的目标服务器。
优点
- 当服务器数量发生变化时,只有少数键需要被重新映射到新的服务器上,这大大减少了缓存失效的数量,提高了系统的可用性。
- 具有良好的可扩展性,可以动态地添加或删除服务器。
缺点
- 在哈希环偏斜的情况下,大部分的缓存对象很有可能会缓存到一台服务器上,导致缓存分布极度不均匀。
- 实现较为复杂,需要引入虚拟节点等技术来解决哈希偏斜问题。
参考资料