格灵深瞳后台开发一面
本文最后更新于 2024年8月12日 晚上
格灵深瞳后台开发一面
全程开放题,可能跟公司开发用Go语言有关,面试官没法问太细的技术要点。
实习的期望和目标是什么
- 个人层面:希望能够在实习过程中通过实践学习提高自己的技术能力,能够学习到真正的企业级开发所必备的技能。
- 公司层面:如果有幸能够加入公司这个大团队,希望在自己力所能及的范围内,做出自己的一份贡献。
为什么拿RPC框架来练手
现在的开发项目大多是分布式架构,不同于以前的单体架构。所以通过对RPC框架的学习,能够学习到基本的分布式设计思想,在写项目的过程中,也了解了服务限流、服务熔断的概念和实现方法,以及负载均衡的算法实现,这些可以为以后做更大的项目打下坚实的基础。
做项目有哪些收获
- 在通信方面,明白了Netty相对于Socket的优势
- 明白了分布式设计的基本思想
- 学会了Zookeeper和Netty的基本使用
- 学会了限流、熔断以及负载均衡的基本思想及其实现
如何对比序列化协议哪个好的,为什么protobuf更高效呢
json是以传字符串的格式在网络中进行传输的,而Protobuf是采用二进制编码格式来传输
- 序列化和反序列化的时间:使用JMH和Faker来进行了测试,发现protobuf的序列化和反序列化时间都比json要小
- 占用内存:Protobuf比JSON少了45个byte。由于ProtoBuf采用二进制格式,数据结构更为紧凑,因此在序列化和反序列化过程中所需的内存较少。Protobuf比JSON序化以后占用的字节数更少,在网络传输的过程中Protobuf更具有优势。
- 对开发者的友好程度:JSON 开发者能够很好的识别,而Protobuf会出现乱码的情况。这里说明了一个问题:在对程序员的友好程度上JSON优于Protobuf。而且使用Protobuf还需要实现定义一个有关传输对象的数据结构文件,而json在序列化的过程中,可能导致数据类型改变,那么在反序列化时还要检查数据类型是否匹配,否则强制转换。
http请求针对回过程详细叙述一下
用生活中的实例场景来类比计算机网络
计算机网络主要是负责计算机之间的通信。
快递在现实生活中的应用
读书期间是否做过比较用心的项目
平常用git吗
为什么用kafka呢,不用其他的呢


讲一讲kafka架构
一文带你搞懂 Kafka 的系统架构(深度好文,值得收藏) - Data跳动 - 博客园 (cnblogs.com)
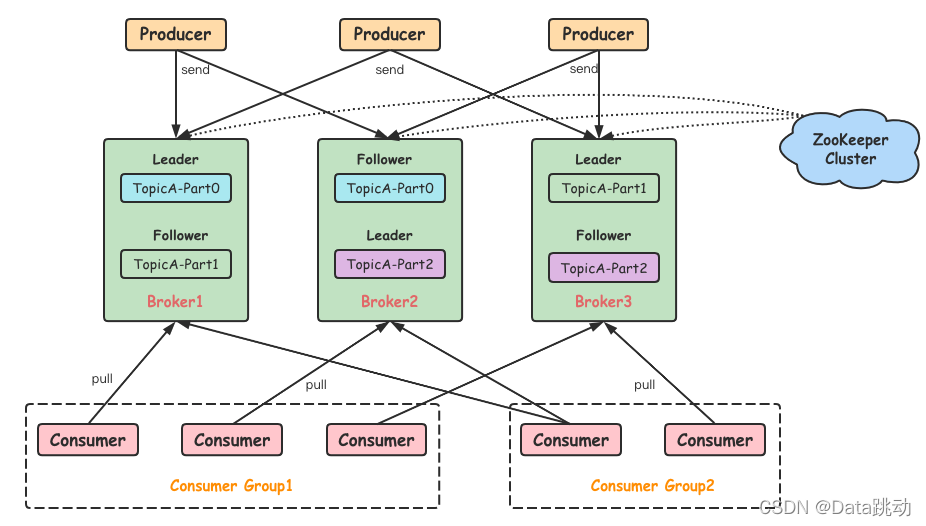
- Producer:生产者,负责将客户端生产的消息发送到 Kafka 中,可以支持消息的异步发送和批量发送;
- broker:服务代理节点,Kafka 集群中的一台服务器就是一个 broker,可以水平无限扩展,同一个 Topic 的消息可以分布在多个 broker 中;
- Consumer:消费者,通过连接到 Kafka 上来拉取消息,用于相应的业务逻辑处理。
- Topic:消息是以 Topic 为单位进行归类的,Topic 在逻辑上可以被认为是一个 Queue,Producer 生产的每一条消息都必须指定一个 Topic,然后 Consumer 会根据订阅的 Topic 到对应的 broker 上去拉取消息;
- Partition:为了提升整个集群的吞吐量,Topic 在物理上还可以细分多个分区,一个分区在磁盘上对应一个文件夹。由于一个分区只属于一个主题,很多时候也会被叫做主题分区
为什么计算机里面有些小数不能表示出来

除了学习你有其他兴趣爱好吗
你有没有特别喜欢的技术博主,哪些品质你觉得时榜样
算法
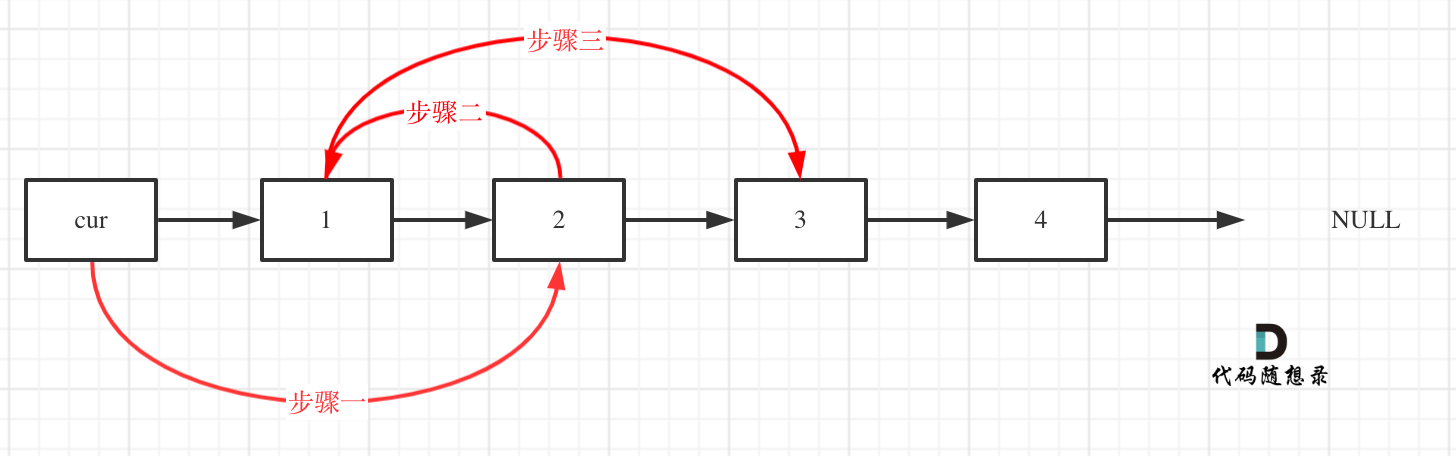
1 | |
格灵深瞳后台开发一面
https://love-enough.github.io/2024/08/12/格灵深瞳后台开发一面/